EURODECISION renforce son expertise historique en mathématiques décisionnelles et aide à la décision en créant l’OpenLab AI.DA.
Nos ambitions :
- En interne et pour nos clients, être un lieu d’échanges et de rencontres pour diffuser les bonnes pratiques, former et capitaliser sur les solutions IA.
- Privilégier une innovation pragmatique ciblée sur les besoins métiers, en étant un trait d’union entre état de l’art en recherche, développements informatiques et le terrain.
- Pouvoir faire appel, selon les problèmes, à toutes les familles de l’Intelligence Artificielle, pas seulement les réseaux de neurones, voire, souvent, à une combinaison de ces techniques algorithmiques et d’expertise métier.
- Développer des méthodologies et outils de traitement et d’analyse de la donnée, et participer à l’écosystème open source autour de la data.
24 octobre 2022
La version 8.0 du logiciel LP-Toolkit d’EURODECISION vient de sortir !
Les nouveautés :
– Support de la version 2.10.5 de COIN Branch and Cut solver (CBC) (support du parallélisme sous windows)
– Support de la version 22.1.0 de IBM CPLEX
– Support de la version 5.0 de GLPK
– Support de la version 9.5.1 de Gurobi
– Support de la version 8.14.0 de FICO Xpress
– Simplification de l’interface programmeur (API)
LP-Toolkit permet de développer (modélisation, prototypage, test, industrialisation) en C++ des moteurs d’optimisation reposant sur la programmation mathématique, indépendamment du solveur utilisé. Il apporte tous les outils nécessaires pour construire et tester rapidement un modèle de programmation linéaire et permet de se concentrer essentiellement sur le modèle en simplifiant au maximum les interfaces entre les données utilisateur et le solveur de base dont il est indépendant.
Nos équipes R&D développent des packages python pour la data et le machine learning
– Pandas-cleaner : une extension de la librairie open source Pandas pour détecter, analyser et nettoyer les erreurs dans les données.
– Eduardo : un ETL no code, basé sur la librairie open source Taipy.
– ED-Mind : un framework C++ et une API python pour faciliter le développement et l’entraînement de modèles d’apprentissage par renforcement.
Pandas-cleaner, une nouvelle librairie open source python pour la data science
EURODECISION est fière de participer à l’écosystème open source data et est heureuse d’annoncer la release de son outil pandas-cleaner sous licence BSD-3.
Pandas-cleaner est une extension de pandas pour :
– détecter différents types d’erreurs (valeurs manquantes, aberrantes, mal formattées, incohérentes…) sur différents types de données (numériques, catégorielles et textuelles) via une API simple,
– analyser les erreurs potentielles, via des rapports et des graphiques pour décider si une correction est nécessaire,
– nettoyer les dataframes en, selon les cas, supprimant les données erronées, les remplaçant, les corrigeant automatiquement etc.
Installation : pip install pandas-cleaner
5 janvier 2023
ED-Mind, un nouveau composant pour le développement de modèles industriels d’apprentissage par renforcement
ED-Mind a été conçu pour :
- Hybrider des composants d’optimisation développés en C++ avec des modèles Python
- Créer des environnements Gym, compatibles avec des librairies d’apprentissage par renforcement
- Et ainsi tester des approches d’optimisation innovantes basées sur le deep learning
9 janvier 2023
EDUARDO : un nouveau composant pour la gestion des pipelines data
Chez EURODECISION, nous utilisons beaucoup de données clients pour alimenter nos modèles de recherche opérationnelle ou de machine learning. Ces données sont rarement utilisables de manière brute et doivent être transformées, nettoyées, réorganisées, agrégées.
De nombreux outils d’ETL et ELT existent pour cela, souvent optimisés pour des big datawarehouses dans le cloud. Mais, en pratique :
- La partie transformation des données est toujours très spécifique au projet.
- Les datas ne sont pas toujours Big ou dans le cloud.
- Tout le monde ne parle pas le SQL !
Nos équipes R&D ont donc développé un outil spécifique pour ces cas. Nom de code : EDUARDO.
Package python :
– utilisable en local ou déployable
– extensible
Pipelines définies via des fichiers texte en yaml :
– compréhensibles par des non-développeurs
– maintenables et collaboratives avec git
– visualisables sous forme de DAGs dans le navigateur
Basé, sous le capot, sur des librairies open source :
– Pandas et ses nombreuses fonctionnalités
– Le récent et puissant Taipy Core pour gérer les dépendances entre tâches
– Pandas-cleaner pour le nettoyage automatisé
13 janvier 2023
ED-Rules : une plateforme logicielle Java facilitant l’utilisation de Drools, la technologie BRMS (systèmes à base de règles) open source de référence.
ED-Rules se révèle particulièrement utile pour les cas suivants :
- Créer rapidement un prototype de moteur de règles ou un démonstrateur,
- Poser les bases d’une application BRMS complète encapsulant le moteur Drools,
- Modéliser et automatiser des processus de décision basés sur des concepts métier (base de connaissances, logique métier exprimée sous forme de règles et tables de décision).
La plateforme dispose d’une IHM web et offre de nombreuses fonctionnalités : création de session Drools, segmentation des données, génération de modèle Java ou de modèle déclaratif (par exemple à partir d’un fichier .csv), gestion de versions, synchronisation à l’éditeur Drools Workbench et plus encore.
Et tout ça sans deep learning ni réseaux de neurones … Car l’intelligence artificielle c’est aussi l’IA Symbolique !
Pour en savoir plus sur les BRMS :
Demandez notre livre blanc « Le BRMS brique par brique »
Découvrir notre formation Business Rules Management Systems (BRMS)
28 février 2023
L’OpenLab AI.DA se penche sur la maintenance prédictive
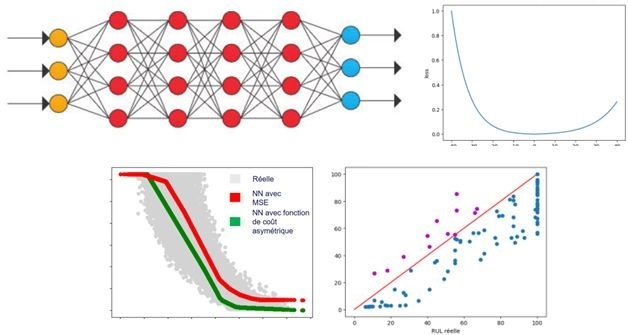
Pour des véhicules autonomes, il est préférable de surestimer la consommation électrique (donc de sous-estimer la distance à parcourir) pour éviter de tomber en panne.
En maintenance prédictive, il ne faut pas surestimer la durée de vie restante d’un équipement. En effet, prévoir une panne juste après la panne réelle ne sert à rien, même si on se trompe très peu …
Or, en machine learning, les fonctions d’erreur sont généralement symétriques (par exemple la MSE en régression). C’est-à-dire qu’une erreur de surestimation a la même importance qu’une erreur de sous-estimation. Une solution classique est d’ajouter une marge, a posteriori, aux résultats d’un modèle de prédiction.
Et si nous prenions en compte cette problématique dès l’entraînement du modèle ? Pour y répondre, nous avons lancé des travaux de R&D sur la modélisation de fonctions d’erreur asymétriques dans des réseaux de neurones (en utilisant les librairies Keras et TensorFlow). Les premiers résultats sont prometteurs (après application sur des pannes de turboréacteurs, et comparaison avec d’autres méthodes de machine learning) !
13 mars 2023
GenDM : générateur de code C++
Utilisé dans la majorité des modèles et algorithmes d’optimisation développés par les ingénieurs d’EURODECISION, GenDM génère automatiquement du code C++ sur la base d’un fichier d’entrée décrivant un modèle objet, afin de :
- Raccourcir les cycles de développement,
- Faciliter la mise à jour du modèle objet d’un moteur d’optimisation,
- Sérialiser dans différents formats (JSON, XML, CSV),
- Produire un code sûr et respectant des principes de qualité logicielle (gestion mémoire, encapsulation…),
- Garantir des codes homogènes entre les différents projets d’EURODECISION,
- Garantir des codes maintenables,
- Fournir des diagrammes UML et visualiser les différentes relations (héritage, composition…).
GenDM permet ainsi aux ingénieurs de consacrer plus de temps au code « intelligent », i.e. au code des moteurs d’optimisation.
3 avril 2023
LP-Scheduler : nouvelle version du composant de planification de tâches sous contraintes de ressources
Ce moteur d’optimisation générique permet de modéliser et de résoudre des problèmes de planification opérationnelle et d’ordonnancement :
- En prenant en compte des contraintes :
– liées aux ressources : caractéristiques des ressources disponibles (calendrier de disponibilité, ressources identiques, exclusions entre ressources…), compétences des ressources et état d’une ressource, liste des affectations tâches-ressources (compétences nécessaires, utilisation, consommation, génération, absorption, délai après le début / avant la fin…), contraintes temporelles et géographiques (temps de déplacement des ressources d’un lieu à un autre …) ;
– liées aux tâches : caractéristiques des tâches à effectuer (date de début au plus tôt / tard, durée, priorité, tâche sécable ou non, calendrier de démarrage ou de fin, tâches regroupées), liens entre les tâches / groupes de tâches et contraintes temporelles (précédence fin-début / début-début / fin-fin / début-fin, délai minimum/maximum, incompatibilité entre 2 tâches, tâches calées, respect des dates…) ; - En optimisant plusieurs critères : minimisation de la durée totale pour toutes les tâches planifiées (= fin au plus tôt), planification au plus tôt / tard pour les tâches en dehors du chemin critique, minimisation de l’effectif de personnel, minimisation du coût total, lissage de l’activité… ;
- En garantissant des temps de calcul très performants et adaptés à une utilisation en temps réel / temps contraint, par exemple dans des contextes de chaîne de production automatisée et d’usine connectée.
D’un point de vue technique, LP-Scheduler est :
– développé en C++, avec une API Python ;
– basé sur des heuristiques constructives ;
– fortement paramétrable et évolutif, pour s’adapter facilement à différents besoins métier.
20 septembre 2023
ED-MDAO, un nouveau composant Python pour le développement d’applications de MDAO (analyse et optimisation de conception multidisciplinaire)
ED-MDAO a été conçu pour :
- Résoudre des problèmes d’optimisation de la conception de produits et de processus industriels, en prenant en compte plusieurs disciplines de la physique et de l’ingénierie.
- Utiliser, configurer, adapter et développer des pipelines et des modèles d’aide à la décision : génération de plans d’expériences, construction de modèles statistiques de substitution, optimisation multiobjectif et recherche de fronts de Pareto, analyse des solutions obtenues.
Les principales fonctionnalités et spécificités du composant ED-MDAO sont :
- Génération de plans d’expériences : méthodes Monte-Carlo et quasi-Monte-Carlo, plans contraints, plans fractionnaires…
- Modèles statistiques de substitution (classification et régression) : automatisation de la sélection de modèles, cross validation, définition de plusieurs métriques d’évaluation, gestion de plusieurs sorties en simultané, normalisation ou non des données, transformation des variables et des réponses…
- Optimisation multi-objectifs : optimisation blackbox et algorithmes évolutionnaires, prise en compte de variables entières et qualitatives…
- Analyse et visualisation des résultats (essais et modèles statistiques) : Morris, Sobol, corrélations…
D’un point de vue technique, ED-MDAO est basé sur les librairies Python open source suivantes : Scikit-learn, Pandas, SciPy, pymoo, jMetalPy, XGBoost, SALib, OpenTURNS, pyDOE, seaborn, Matplotlib.
5 décembre 2024
IA Générative : L’OpenLab AI.DA met en place des RAGS en interne
- Pour rappel, un chatbot RAG (génération augmentée par récupération de données) est un LLM qui, couplé à une base de documents, permet aux utilisateurs de poser des questions sur un domaine particulier (doc technique, doc commerciale, données internes…).
- Nous avons développé plusieurs pipelines rag via le framework Langflow en python. Ces pipelines tournent sous docker, et sont donc déployables sur n’importe quelle architecture (cloud ou on-premise).
- Chaque pipeline rag est composée de plusieurs modèles d’IA Générative servis par Ollama et embarque des vector-stores prêts à l’emploi (MongoDB Atlas).
- Notre objectif est de pouvoir déployer rapidement et facilement un chatbot RAG spécialisé en interne ou chez nos clients.
- Par exemple : pipeline interne dédiée à la recherche d’informations dans nos supports de formation en Intelligence Artificielle.