Qu’est-ce que le machine learning ?
Le machine learning, ou apprentissage statistique, est un domaine de la modélisation statistique et de l’intelligence artificielle.
L’objectif du machine learning est de reconnaître parmi des données des structures souvent trop difficiles à détecter ou à mesurer manuellement. À partir de ces structures, on peut chercher à classifier des individus, des objets, à prédire la valeur d’une variable à un certain horizon, à expliquer l’apparition ou non d’une caractéristique.
Le machine learning est par exemple utilisé pour :
- prédire la quantité de ventes d’un produit sur les trois prochains mois, en fonction des ventes observées sur le même produit dans le passé,
- créer une classification de la clientèle en fonction de caractéristiques socio-démographiques et des achats passés,
- attribuer un score à une personne indiquant si celle-ci est sur le point de se désabonner d’un produit ou non,
- reconnaître automatiquement un chiffre manuscrit ou un visage.
Au-delà d’une ou deux variable, il devient difficile de voir à l’œil nu des structures dans les données, c’est à ce niveau que l’apprentissage statistique, ou machine learning, trouve tout son intérêt. Il en est de même lorsque le nombre d’individus (d’observations) augmente.
Exemple d’utilisation du machine learning
Prenons un exemple : on cherche à déterminer si une personne, dans la base de données d’un magasin de chaussures, va cliquer sur le lien contenu dans le mail promotionnel qui lui a été envoyé. Pour cela, nous observons dans un premier temps l’historique, dont voici un extrait :
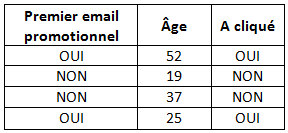
Ici, les observations, ou individus, sont les contacts de la base de données. Ils ne sont pas forcément clients de la marque. Les variables explicatives, indicateurs, ou encore caractéristiques, sont l’âge, et le fait que ce soit le premier email envoyé ou non.
La variable à expliquer, ou variable cible, est ici le fait qu’un client ait cliqué ou non sur le lien de l’email. Dans l’historique, nous connaissons la valeur de cette variable. L’objectif est de déduire, à partir de cet historique justement, que nous appelons population d’apprentissage, la valeur que prendra cette variable cible pour de nouveaux individus, faisant partie d’une population test. Le but est de trouver la règle qui se trompera le moins possible sur cette variable cible. Cette règle sera le plus souvent créée par un algorithme complexe de machine learning et sera généralement très difficile, ou impossible, à expliciter.
Dans cet exemple, manuellement nous pouvons deviner une structure simple, et simpliste ici, qui serait : « S’il s’agit du premier email promotionnel envoyé à un client, alors l’individu clique ». Or, si on considère une base de données plus grande, on constate que cette règle très simple devient fausse :
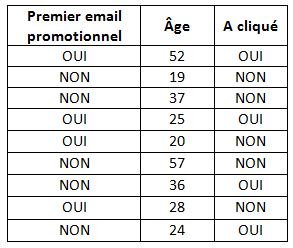
On comprend alors que l’âge et le fait de savoir s’il s’agit du premier email ou non ne suffisent pas à détecter la structure réelle des données. Pour cela, nous avons besoin de données supplémentaires, comme par exemple le sexe de la personne, si elle a acheté récemment ou non, si elle a cliqué sur le lien de l’email précédent ou non.
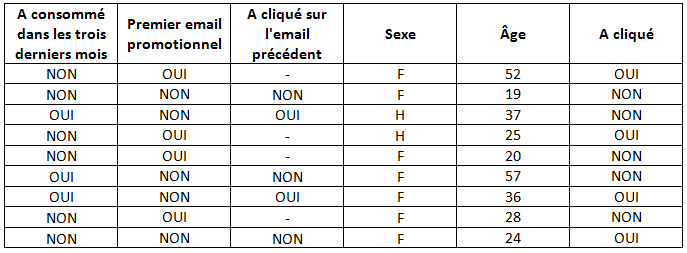
Avec ces nouveaux indicateurs, il devient beaucoup plus difficile de trouver une structure de données basique. De simples règles ne suffisent plus, surtout qu’il n’existe sûrement pas de règle généralisable dans cet exemple. Il faut alors trouver un modèle statistique, qui fournira, pour chaque individu, selon ses critères, la probabilité qu’il clique sur le nouveau lien promotionnel.
Contrairement à l’être humain, pour qui une grande quantité de données peut rendre l’étude plus compliquée, les algorithmes de machine learning s’en enrichissent.
Si le nombre de lignes devient supérieur à 100 000, ou 100 000 000 par exemple, il est extrêmement difficile, voire impossible, de détecter manuellement une structure sous-jacente entre les individus et les variables. Le machine learning va alors chercher à appliquer des méthodes de modélisation statistique sur ce très grand jeu de données, afin de trouver la structure donnant les meilleurs résultats, c’est-à-dire celle qui donnera lieu au taux d’erreur le plus faible.
Le machine learning, combiné aux méthodes récentes de big data, permettent en effet de traiter des jeux de données de plus en plus volumineux, tant en termes d’observations que de variables.
Parmi les algorithmes de modélisation statistique les plus connus, nous trouvons la régression linéaire, la régression logistique, les arbres de classification et de régression, l’analyse factorielle, les support vector machine, les réseaux de neurones… Il existe également de nombreuses façons de combiner ces méthodes afin d’en trouver une meilleure : boosting, vote, forêt…
En savoir plus :