Qu’est-ce que la Data Science ?
La Data Science est un domaine interdisciplinaire dont le but est d’analyser des quantités importantes de données et d’en extraire des connaissances. Elle intègre des méthodes issues de l’informatique, des statistiques, du machine learning, de l’analyse de données et des mathématiques décisionnelles.
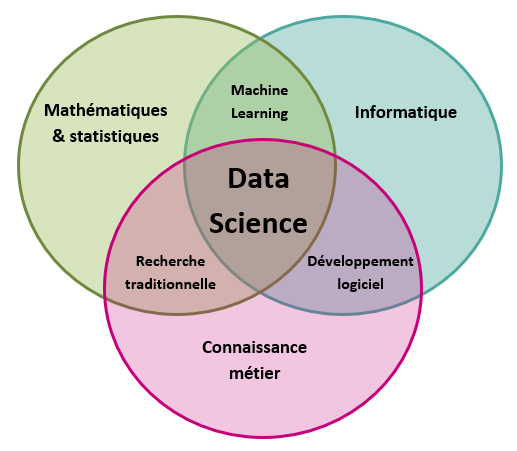
La Data Science permet d’exploiter les données afin de modéliser des comportements, de prendre des décisions, ou de faire des prédictions en utilisant des algorithmes.
La Data Science est ainsi constituée d’outils et de méthodes permettant de :
- Structurer et organiser les données dans des bases de données, des entrepôts de données (data warehouses) et des datamarts, en faisant éventuellement appel à des ontologies et au big data;
- Collecter, intégrer et agréger des données à partir de plusieurs sources, éventuellement hétérogènes, à l’aide d’outils d’ETL;
- Valider, contrôler et nettoyer les données, par exemple à l’aide de règles métier (BRMS);
- Visualiser et diffuser les données, sous forme de tableaux de bord et de reportings, à l’aide d’outils de BI (Business Intelligence) et de dataviz;
- Apprendre à partir de ces données, en utilisant des algorithmes de statistiques et de machine learning : régression linéaire (simple, multiple), régression logistique, clustering (K-means, KNN, DBSCAN, …), arbres de décision et forêts d’arbres décisionnels (Random Forest), Support Vector Machines (SVM), réseaux de neurones, boosting séries temporelles, analyse en composantes principales, analyse factorielle des correspondances, text mining, apprentissage par renforcement (reinforcement learning)…
Pourquoi la Data Science ?
Dans un environnement concurrentiel où les données ne cessent de circuler, les décideurs peuvent compter sur la Data Science pour analyser leurs données afin de faire émerger des informations cachées pouvant les aider à prendre des décisions plus avisées concernant leur business. Ces décisions basées sur des données peuvent conduire à une rentabilité accrue, à une meilleure efficacité opérationnelle, à une performance commerciale optimisée et à des flux de travail améliorés. Par exemple, dans le domaine de la distribution, de la banque, de l’industrie ou du transport :
- Prévision de la demande, prévision des ventes
- Détection de fraude
- Classification et scoring de clients
- Pricing dynamique et recommandations de prix
- Recommandations de produits à partir de l’expérience client
- Analyse et reconnaissance d’images, de vidéos, de texte…
- Diagnostic de pannes
- Maintenance préventive.
La Data Science en pratique
Afin de mener à bien un projet Data Science, il est très important de suivre toutes les étapes du cycle de vie afin d’assurer le bon fonctionnement du projet. Les étapes à suivre pour réussir un projet de Data Science sont décrites dans le graphique ci-dessous :
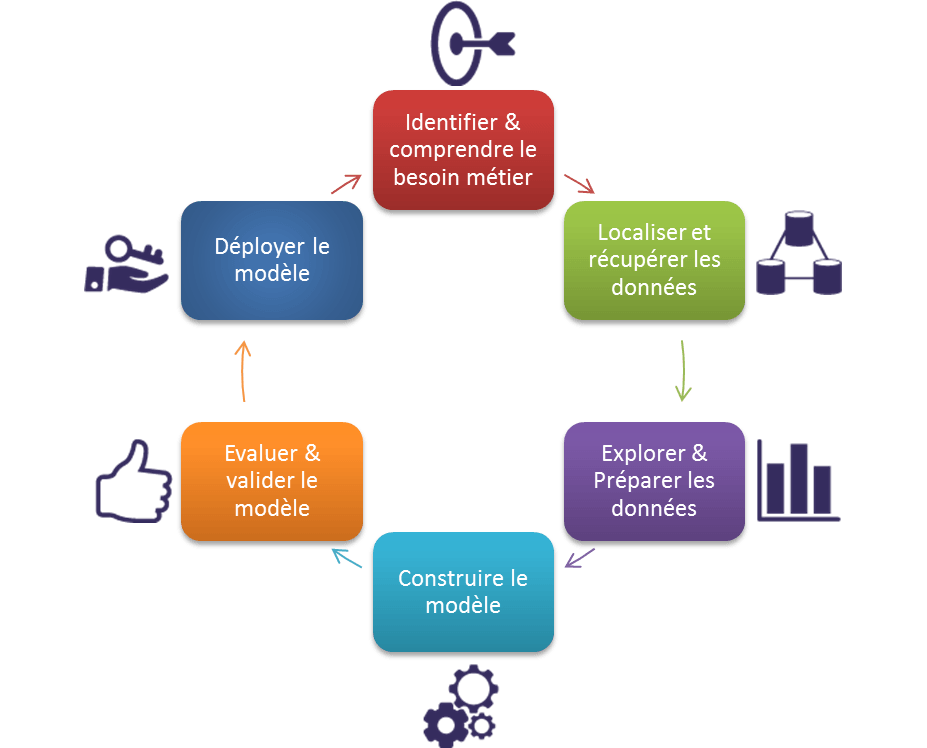
La première étape consiste à comprendre le besoin métier, les différentes spécifications, exigences et priorités.
Ensuite, il faut identifier les données nécessaires pour le développement de la solution, puis les récupérer et les stocker (bases de données opérationnelles, fichiers, site web, etc…).
La troisième phase consiste à préparer les données : classement des données en fonction de critères choisis, nettoyage des données (données manquantes par exemple), et surtout leur recodage pour les rendre compatibles avec les algorithmes qui seront utilisés (Features Engineering).
La quatrième étape est la phase de modélisation qui comprend le choix, le paramétrage et le test de différents algorithmes.
Vient ensuite la phase d’évaluation qui vise à vérifier le(s) modèle(s) ou les connaissances obtenues afin de s’assurer qu’ils répondent aux objectifs formulés au début du projet. C’est dans cette phase que l’on décide si le modèle est assez robuste et donc prêt au déploiement, ou bien s’il faut l’améliorer encore.
L’étape finale du cycle de vie consiste en une mise en production pour les utilisateurs finaux des modèles développés.
La boîte à outils d’un Data Scientist
Quelques outils souvent utilisés pour un projet de Data Science chez EURODECISION :
- Bases de données : Oracle, MySQL, PostGreSQL
- ETL : Talend
- Big Data : Hadoop, Spark
- Plateformes « statistiques & machine learning » : R, Python
- Outils de BI et dataviz : Qlikview/Qliksense, SiSense, PowerBI, Looker, Tableau
- Outils de BRMS : Drools, ODM (JRules)
Découvrez le Calendrier de l’Avent du Data Scientist : chaque jour du mois de Décembre 2022, Renan Hilbert, Lead Data Scientist, a proposé une librairie python open source autour de la data et de l’IA, testée et approuvée par l’équipe Data d’EURODECISION.